Investigación
Uso clínico de datos sintéticos
¿Qué es un dato sintético y cómo puede ser utilizado en la investigación clínica?

He estado viendo algunos casos y artículos que utilizan datos sintéticos con fines de investigación médica, así que decidí investigar un poco más sobre este tema.
0. ¿Qué son los datos sintéticos?
Obtener datos de alta calidad es un proceso tedioso y costoso. ¿Quieres entrenar un modelo de aprendizaje automático o una red neuronal artificial, pero te falta la cantidad de datos necesaria para el entrenamiento? Es una situación común. Obtener buenos datos siempre es un desafío.
Pero siempre buscamos caminos eficientes. Una de las iniciativas para entrenar redes neuronales artificiales sin una gran cantidad de datos de calidad es el uso de datos sintéticos. Los datos sintéticos son datos generados para imitar los datos del mundo real (Real-World Data, RWD). La ventaja no solo reside en resolver el problema de la falta de datos. También se consideran una alternativa para prevenir la filtración de información personal cuando se comparten datos entre instituciones. Por ejemplo, si la institución A comparte datos directamente con B, podría haber una filtración de información personal contenida en los datos de A, pero si se comparten datos sintéticos basados en los datos de A, se puede mantener la información importante al tiempo que se reduce significativamente la preocupación por la filtración de datos personales.
1. Algoritmos de generación de datos sintéticos
Existen diversos algoritmos utilizados para la generación de datos sintéticos, pero el método más conocido es la Red Generativa Antagónica (Generative Adversarial Network, GAN).
Red Generativa Antagónica (GAN)
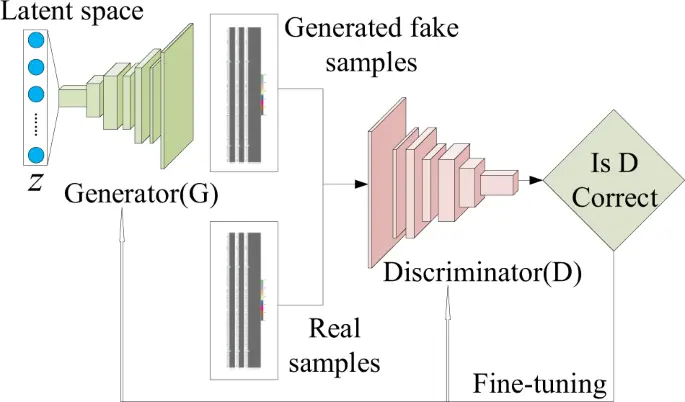 La GAN está compuesta por dos redes neuronales, el generador (Generator) y el discriminador (Discriminator). Ambas redes compiten entre sí, el generador crea datos sintéticos y el discriminador intenta distinguir entre estos datos y los datos reales. A lo largo de este proceso, el generador crea datos cada vez más cercanos a los reales, hasta que el discriminador ya no puede distinguir entre los datos reales y los sintéticos.
La GAN está compuesta por dos redes neuronales, el generador (Generator) y el discriminador (Discriminator). Ambas redes compiten entre sí, el generador crea datos sintéticos y el discriminador intenta distinguir entre estos datos y los datos reales. A lo largo de este proceso, el generador crea datos cada vez más cercanos a los reales, hasta que el discriminador ya no puede distinguir entre los datos reales y los sintéticos.
También existen conceptos derivados de las GAN como el DPGAN (Differentially Private GAN) o el CTGAN (Conditional Tabular GAN). DPGAN introduce el concepto de privacidad diferencial para proteger la información personal contenida en los datos de entrenamiento. CTGAN se diseñó para superar las limitaciones de la GAN al tratar con variables categóricas. Mediante la técnica de generación condicional, CTGAN puede modelar relaciones complejas entre diferentes tablas de datos y generar bien datos mixtos complejos.
VAE (Autoencoder Variacional)
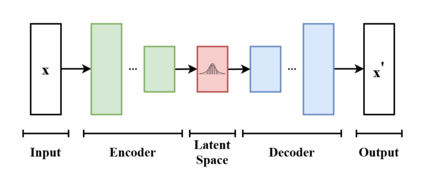 VAE es un modelo de red neuronal que aprende el espacio latente de los datos para generar nuevos datos. VAE está compuesta por un codificador (Encoder) y un decodificador (Decoder). El codificador convierte los datos de entrada en variables latentes y el decodificador genera nuevos datos similares a los originales a partir de estas variables latentes.
VAE es un modelo de red neuronal que aprende el espacio latente de los datos para generar nuevos datos. VAE está compuesta por un codificador (Encoder) y un decodificador (Decoder). El codificador convierte los datos de entrada en variables latentes y el decodificador genera nuevos datos similares a los originales a partir de estas variables latentes.
VAE supone que el espacio latente tiene una distribución normalizada, lo que resulta en datos generados que son continuos y suaves.
SMOTE (Synthetic Minority Over-sampling Technique)
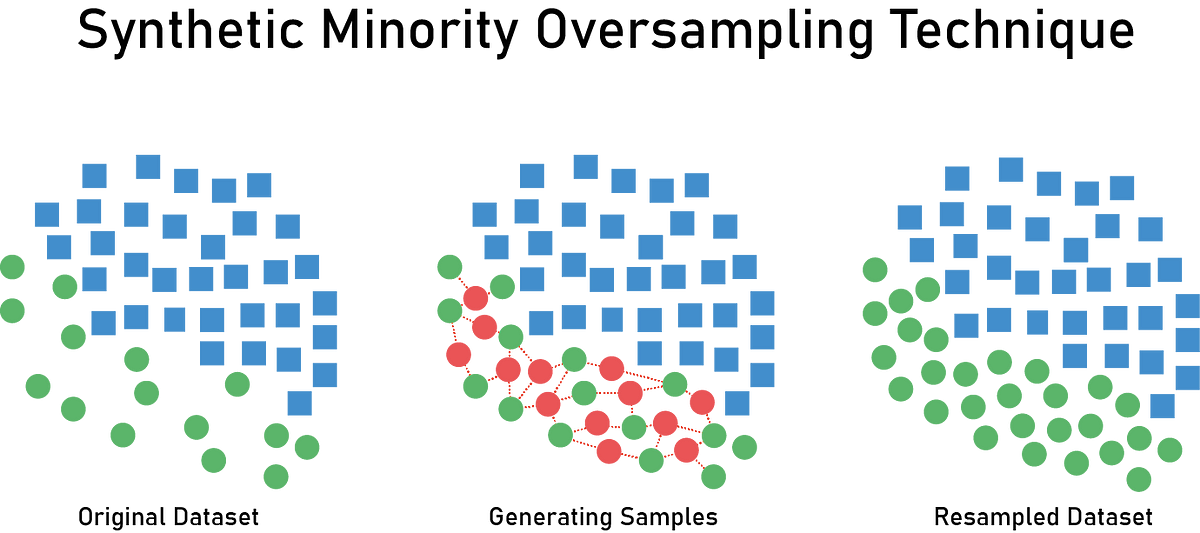 Al usar machine learning y deep learning, es posible encontrarse con clases minoritarias dentro del dataset. Por ejemplo, los datos de pacientes con enfermedades raras son abrumadoramente escasos en comparación con otros datos. Esta situación se denomina desequilibrio de datos (data imbalance). SMOTE (Synthetic Minority Over-sampling Technique) es una técnica comúnmente utilizada para resolver esta situación.
Al usar machine learning y deep learning, es posible encontrarse con clases minoritarias dentro del dataset. Por ejemplo, los datos de pacientes con enfermedades raras son abrumadoramente escasos en comparación con otros datos. Esta situación se denomina desequilibrio de datos (data imbalance). SMOTE (Synthetic Minority Over-sampling Technique) es una técnica comúnmente utilizada para resolver esta situación.
SMOTE genera nuevos datos entre las clases minoritarias existentes utilizando el algoritmo de k-vecinos más cercanos (K-nearest neighbor). (En la imagen de arriba, los círculos rojos) Aunque generalmente, al hablar de generación de datos se refieren más a métodos como GAN y VAE que a upscaling con SMOTE, técnicamente SMOTE también entra en la categoría de generación de datos sintéticos, así que lo hemos incluido.
Pueden existir otras técnicas, pero no tengo un amplio conocimiento sobre algoritmos como para profundizar. Solo tengamos en cuenta que existen varios métodos.
2. Consideraciones al usar datos sintéticos
Si pudiéramos generar datos (similares a la realidad) fácilmente, sería estupendo, pero no es así. Hay consideraciones importantes.
Mitigación de sesgo
Si los datos originales están sesgados, es probable que los datos sintéticos también lo estén. Por lo tanto, al generar datos sintéticos, es necesario identificar y corregir los sesgos presentes en los datos originales. Si no se hace esto, el modelo podría entrenarse con datos sesgados y generar predicciones inexactas.
Asegurar la representatividad
Como se mencionó antes, los datos sintéticos deben ser similares a los datos reales. Esto significa que los datos originales también deben abarcar diversas situaciones y, al mismo tiempo, los datos generados deben reflejar de manera realista variadas situaciones para representar bien la realidad en la que vivimos. Para que un modelo entrenado con datos sintéticos funcione bien en situaciones reales, este aspecto es crucial.
Cumplimiento de reglamentaciones
Esto es especialmente importante cuando se utilizan datos sintéticos con fines médicos. Los datos sintéticos deben cumplir con los requisitos relacionados con la información personal y médica, como HIPAA o GDPR. Esto es particularmente crítico al utilizar datos médicos o relacionados con información personal. Incluso al usar datos sintéticos, se deben cumplir estas regulaciones para garantizar la privacidad y seguridad de los datos.
3. Evaluación de los datos sintéticos
Cuando escuché hablar sobre los datos sintéticos, mi primer pensamiento fue este.
¿Cómo evaluar si los datos generados son similares a los reales?
El objetivo no es simplemente crear datos, sino generar datos similares a los reales para aprovecharlos. Por lo tanto, es crucial evaluar cuánto imitan y reproducen los datos sintéticos las situaciones reales.
Uso como ejemplo varios resultados del artículo recientemente publicado en NPJ Digital Medicine (Mimicking clinical trials with synthetic acute myeloid leukemia patients using generative artificial intelligence) para mostrar cómo se puede evaluar los datos sintéticos. En dicho artículo, se generaron datos sintéticos de pacientes con leucemia mieloide aguda utilizando dos algoritmos diferentes (CTAB-GAN+, NFlow).
3.1. Similitud estadística
En resumen, se trata de verificar si los datos sintéticos tienen las mismas características estadísticas que los originales. Por ejemplo, la media y la desviación estándar de la edad del cohorte de datos sintéticos no deben presentar diferencias estadísticas significativas con los datos originales. El artículo mencionado compara las características estadísticas del cohorte formado por datos sintéticos con las de los datos originales como se muestra en la siguiente tabla.
 Comparación de las características estadísticas entre los datos generados y los datos originales
Comparación de las características estadísticas entre los datos generados y los datos originales
No entraré en detalles del artículo, pero se puede ver cómo se comparan las características estadísticas como la edad, la distribución de género y el recuento de glóbulos blancos entre los datos sintéticos y los originales. El artículo también evalúa si los datos generados reproducen bien las características genéticas de los datos originales.
 Comparación de las características genéticas entre los datos generados y los datos originales
Comparación de las características genéticas entre los datos generados y los datos originales
3.2. Similitud estructural
Además, los datos sintéticos deben mantener las mismas correlaciones que los datos originales. Por ejemplo, si hay una correlación entre la edad y una enfermedad específica en los datos originales, esto debe aparecer también en los datos sintéticos. El artículo mencionado compara la similitud entre los datos sintéticos y los originales mediante análisis de supervivencia de pacientes con leucemia mieloide aguda.
 Comparación de la similitud estructural entre datos generados y originales mediante análisis de supervivencia
Comparación de la similitud estructural entre datos generados y originales mediante análisis de supervivencia
3.3. Aplicabilidad
También es importante evaluar si los datos sintéticos son tan útiles como los datos reales. Este es el propósito en sí mismo. Por ejemplo, sería ideal que un modelo entrenado con datos sintéticos mostrase un rendimiento similar a uno entrenado con datos reales.
3.4. Conservación de la privacidad
La capacidad de generar datos que protejan la privacidad manteniendo características estadísticas similares a los datos reales es una ventaja de los datos generados. El artículo mencionado también utiliza la protección de la privacidad como un criterio de evaluación de los datos generados. Una de las técnicas empleadas es la distancia de Hamming. Básicamente, mide la distancia entre dos cadenas de la misma longitud y se puede utilizar como una métrica para evaluar el grado de anonimización entre dos datos. Por lo tanto, el artículo usa la distancia de Hamming para medir el grado de anonimización entre los datos generados y los datos originales.
Hasta ahora, he explicado cómo se evalúan los datos generados. Ahora vamos a ver algunos casos de uso clínico de los datos generados. ¡Mis dedos van a doler!
4. Casos de uso clínico de datos generados
4.1 Investigación sobre enfermedades cerebrovasculares
 El artículo en PLoS One publicado en febrero de este año examina en qué medida los datos sintéticos imitan los datos reales en enfermedades cerebrovasculares.
El artículo en PLoS One publicado en febrero de este año examina en qué medida los datos sintéticos imitan los datos reales en enfermedades cerebrovasculares.
El artículo sintetiza datos de pacientes con accidente cerebrovascular isquémico, tanto de pacientes con cáncer como sin cáncer, e informa que los datos sintéticos imitan bien las características demográficas, comorbilidades, duración de la hospitalización y otros criterios de evaluación importantes de los datos originales. En la conclusión, los investigadores destacan que los datos sintéticos son una poderosa herramienta para generar hipótesis, compartir datos y facilitar el acceso rápido y seguro a grandes cantidades de datos.
4.2 Investigación sobre tumores sanguíneos
Además del artículo mencionado anteriormente sobre la evaluación de datos generados, existe otro artículo.

En este estudio, los investigadores sintetizaron datos de pacientes con síndrome mielodisplásico (Myelodysplastic Syndrome, MDS), evaluando datos originales y generados. Utilizando una GAN condicional, demostraron que los datos sintéticos podían replicar con gran precisión las características clínicas, la información genómica y los tratamientos y resultados de los grupos de pacientes. Una parte particularmente impresionante fue que, al realizar la síntesis de datos basados en datos recopilados en 2014, la clasificación realizada con estos datos fue similar a la realizada con datos recopilados en 2024 (véase la imagen siguiente).

Hasta ahora, hemos explorado qué son los datos sintéticos, cómo se generan, cómo se evalúan y algunos ejemplos de uso clínico. Claramente, pueden facilitar el acceso a grandes cantidades de datos, y (suponiendo que los datos sintéticos imiten bien los reales) se pueden compartir datos preocupándose menos por la privacidad y se pueden utilizar para potenciar casos relativamente raros en el entrenamiento. Sin embargo, su uso y evaluación requerirán cautela.
Otras entradas en la misma categoría
Ver Todo →
Reseña del Capítulo de ACP de Massachusetts de la Sociedad Americana de Medicina Interna.
Obtuve la oportunidad de presentar en la sesión de carteles y también obtuve buenos resultados, fue un tiempo significativo.

Vida de investigación junto con datos públicos.
Cualquiera que sea la investigación, el factor más importante es obtener datos de alta calidad. Los datos públicos en cierta medida ayudan a resolver este problema.

Resumen del comentario de la revista digital de salud Ranset de mayo de 2020 (1)
Gestión de grandes exámenes de salud mental, retinopatía diabética y manejo de diarrea en áreas médicamente desfavorecidas.