연구일기
합성 데이터의 임상적 사용
합성 데이터란 무엇이고, 임상 연구에는 어떤 식으로 사용될 수 있을까?

합성 데이터를 의료 연구 목적으로 사용하는 사례나 논문들이 종종 보이길래, 이 부분을 조금 더 깊이 알아보고자 이것저것 찾아보았습니다.
0. 합성 데이터란? (Synthetic Data)
양질의 데이터를 얻는 과정은 번거롭고 비용이 많이 듭니다. 기계학습 또는 인공신경망을 훈련시키고 싶은데 훈련에 필요한 데이터가 부족한 경우? 자주 있는 일입니다. 좋은 데이터를 얻는 과정은 언제나 숙제죠.
하지만 우리는 언제나 효율적인 길을 찾죠. 앞서 말한 양질의, 다량의 데이터 없이도 인공신경망을 훈련하기 위한 시도 중 하나가 합성 데이터의 이용입니다. 합성 데이터는 현실의 데이터(Real-World Data, RWD)를 모방하도록 생성된 데이터인데요. 장점은 데이터 부족 문제 해결에만 있지 않습니다. 기관 간 데이터를 공유할 때 발생할 수 있는 개인정보 유출을 방지하기 위한 대안으로도 조명받고 있더라구요. 이를테면 기관 A가 B와 데이터를 공유할 때, 데이터를 직접적으로 공유하면 A의 데이터 내에 있는 개인정보가 유출될 수 있지만, A의 데이터를 기반으로 한 합성 데이터를 공유한다면 A의 데이터 내부에 있는 중요한 정보는 유지하면서 개인정보 유출에 대한 우려를 상당히 덜 수 있는 식입니다.
1. 합성 데이터 생성 알고리즘
합성 데이터 생성에 사용되는 알고리즘은 여러 가지가 있지만, 가장 잘 알려진 방법은 생산적 적대 신경망(Generative Adversarial Network, GAN)입니다.
생산적 적대 신경망 (GAN)
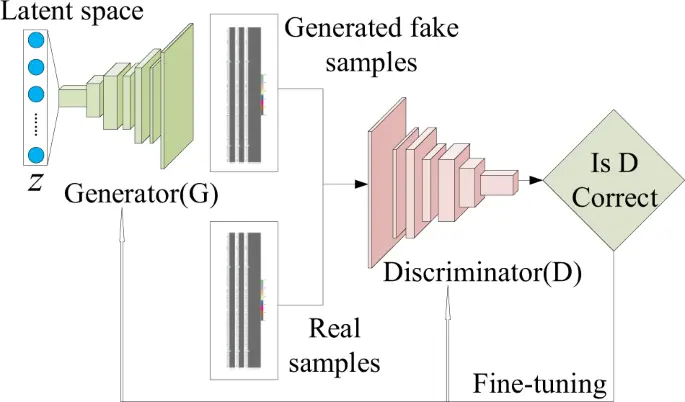
GAN은 두 개의 신경망, 생성자(Generator)와 판별자(Discriminator)로 이루어져 있습니다. 두 신경망은 서로 경쟁하는 관계로, 생성자는 진짜 같은 합성 데이터를 만들고, 판별자는 이를 진짜 데이터와 구분하려 시도합니다. 이 과정에서 생성자는 더 실제 데이터와 근접한 데이터를 만들게 되며, 판별자가 생성된 데이터가 실제인지 아닌지 구분할 수 없을 정도로 실제와 유사한 데이터를 최종적으로 생성하게 됩니다.
GAN에서 발전된 개념으로 DPGAN(Differentially Private GAN)이나 CTGAN(Conditional Tabular GAN)도 있습니다. DPGAN은 Differential Privacy라는 개념을 도입하여 훈련 데이터에 포함된 개인 정보를 보호하도록 설계되었습니다. CTGAN은 범주형 변수를 처리하기 어렵다는 GAN의 한계를 극복하기 위해 설계되었습니다. 조건부 생성(conditional generation) 기법을 도입하여 다양한 데이터 테이블 간의 복잡한 관계를 모델링하여 복잡한 혼합된 형식의 데이터도 잘 생성한다 하네요?
VAE (Variational Autoencoder)
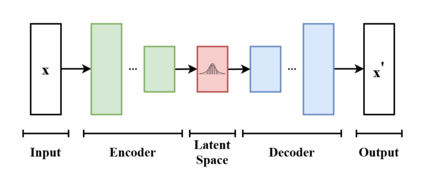
VAE는 데이터의 잠재 공간(latent space)을 학습하여 새로운 데이터를 생성하는 신경망 모델입니다. VAE는 인코더(Encoder)와 디코더(Decoder)로 구성되는데요. 인코더는 입력 데이터를 잠재 변수로 변환하고, 디코더는 이 잠재 변수로부터 원래 데이터와 유사한 새로운 데이터를 생성합니다.
VAE는 잠재 공간을 정규화된 분포로 가정하기에, 생성된 데이터가 연속적이고 부드럽다는 특징을 가지고 있습니다.
SMOTE (Synthetic Minority Over-sampling Technique)
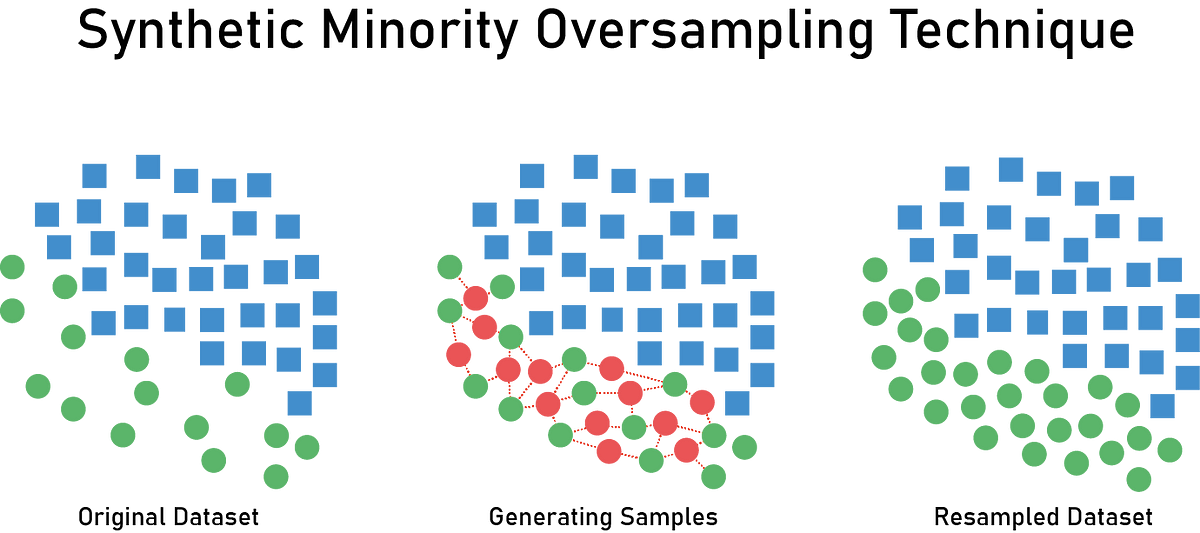
머신러닝, 딥러닝을 이용하다 보면 데이터셋 내에 비교적 적은 수가 존재하는 소수 클래스가 존재합니다. 예를 들면 희귀병 환자의 데이터 숫자는 그렇지 않은 데이터에 비해 압도적으로 드물겠지요. 이런 상황을 데이터 불균형 (data imbalance)라 하는데요. SMOTE (Synthetic Minority Over-sampling Technique)은 이 상황을 해결하기 위해 자주 사용되는 기법입니다.
SMOTE는 k-최근접 이웃 알고리즘 (K-nearest neighbor)을 통해 소수 데이터들 사이에 새로운 데이터를 생성합니다. (위 그림에서 빨간 원들) 일반적으로 생성 데이터라 표현하면 SMOTE로 행하는 upscaling보다는 위에 언급한 GAN, VAE 등을 이용한 데이터 생성을 이야기하지만 엄밀히 말해 SMOTE 역시 합성 데이터 생성의 영역에 들어가기에 포함시켜보았습니다.
뭐 이것 말고도 더 있을 수도 있겠지만, 제가 알고리즘에는 그렇게 해박하지 않은 관계로 자세히 다루지는 않겠습니다. 그럴 깜냥도 안되구요. 이런 여러가지 방법들이 있다 정도만 알고 넘어갑시다.
2. 합성 데이터 사용 시의 고려사항
막 편하게 (실제와 유사한) 데이터를 찍어 낼 수 있다면 당연 좋겠지만, 그건 아니구요. 당연히 중요한 고려사항이 있습니다.
편향 완화하기 (Mitigating bias)
원본 데이터가 편향되어 있을 경우 합성 데이터도 이러한 편향성을 갖고 있을 확률이 높겠죠? 따라서, 합성 데이터를 생성할 때는 원본 데이터에 존재하는 편향을 인식하고 교정하는 작업이 필요합니다. 당연하지만 그렇게 하지 않으면 편향된 데이터를 기반으로 모델이 훈련되게 될거고, 부정확한 예측을 하게 될 우려가 있습니다.
대표성 확보하기 (Securing Representativeness)
합성 데이터는 앞서 말했듯 현실 데이터와 유사해야 합니다. 이 말인즉슨, 모태가 되는 현실 데이터 역시 다양한 상황을 포함하고 있어야 한다는 의미이며, 동시에 이를 기반으로 만들어진 생성 데이터 역시 실제와 유사하게 다양한 상황을 포함하여 우리가 사는 현실을 잘 반영 할 수 있어야 한다는 소리입니다. 합성 데이터로 훈련한 모델이 실제 상황에서 잘 작동하려면 이런 면이 중요하겠죠.
규정 준수하기 (Compliance to Regulations)
이는 합성 데이터를 의료적으로 이용 할 때 특히나 중요한데요. HIPAA나 GDPR 같은 개인 정보, 의료 정보 관련 요건을 합성 데이터는 충족해야 합니다. 이는 특히 의료 데이터나 개인 정보와 관련된 데이터를 사용할 때 중요합니다. 합성 데이터를 사용할 때도 이러한 규정을 준수하여 데이터 프라이버시와 보안을 보장해야 합니다.
3. 합성 데이터의 평가
합성 데이터에 대한 이야기를 들었을 때 제 머릿속에 제일 처음 든 생각은 이것이었습니다.
그래서 만들어진 데이터가 실제랑 유사한지 어떻게 평가할건데?
데이터를 만드는 것 자체가 목적이 아니라, 실제와 유사한 데이터를 만들어 이를 활용하는 일이 목적이니만큼 합성 데이터가 얼마나 실 상황을 모방하고 재현하는지를 평가하는 척도 역시 중요합니다.
최근 NPJ Digital Medicine에 실린 논문 (Mimicking clinical trials with synthetic acute myeloid leukemia patients using generative artificial intelligence)의 여러 결과를 아래에서 예시로 들어 합성 데이터를 어떠한 방식으로 평가 할 수 있는지를. 해당 논문에서는 급성 골수성 백혈병 (Acute Myeloid Leukemia) 환자에 대한 합성 데이터를 서로 다른 두 가지 알고리즘 (CTAB-GAN+, NFlow)을 이용해 만들어 보였습니다.
3.1. 통계적 유사성 (Statistical Similarity)
간단히 말해, 합성 데이터가 원본과 동일한 통계적인 특성을 가지고 있느냐 입니다. 이를테면, 합성 데이터 코호트의 평균 나이 및 나이의 표준 편차가 원본 데이터와 통계적으로 유의한 차이가 없어야 하겠죠. 앞서 언급한 논문에서는 다음 표와 같이 합성 데이터로 형성된 코호트의 통계적 특성을 원본 코호트와 비교합니다.

생성 데이터와 원본 데이터의 통계적 특성을 비교한 모습
논문의 자세한 내용은 다루지는 않겠지만, 합성 데이터가 원본 데이터의 나이, 성별 분포, 백혈구 수치 등과 같은 통계적 특성을 잘 구현했는지 비교한 모습을 알 수 있습니다. 해당 논문에서는 다음과 같이 생성 데이터가 원본 데이터의 유전적 특성을 잘 구현했는지 역시 평가 척도 중 하나로 삼았습니다.

생성 데이터와 원본 데이터의 유전적 특성을 비교한 모습
3.2. 구조적 유사성 (Structural Similarity)
이 외에도, 원본 데이터와 동일한 상관관계를 가져야 합니다. 예를 들어, 원본 데이터에서 나이와 특정 질환 간의 상관관계 있다면, 이는 합성 데이터에서도 동일하게 나타나야 하죠. 예를 들어, 앞서 언급한 논문에서는 합성 데이터와 원본 데이터에서 나타난 급성 골수성 백혈병 환자의 생존 분석을 통해 두 데이터의 유사성을 비교했습니다.

생성 데이터와 원본 데이터의 구조적 유사성을 생존분석을 통해 비교한 모습
3.3 적용 가능성 (Utility)
이 외에도, 합성 데이터가 실제로 현실 데이터를 사용한 만큼의 쓸모를 보이느냐 역시 중요한 척도이죠. 애초에 이게 목적이니까요. 예를 들어, 합성 데이터를 사용하여 훈련된 모델이 원본 데이터를 사용하여 훈련된 모델과 유사한 성능을 보여야 이상적이겠죠.
3.4. 개인정보 보호 (Privacy Conservation)
개인정보를 보호하며 원본 데이터와 유사한 통계적 특성을 가진 데이터를 만들 수 있다는 점이 생성 데이터의 장점이니만큼, 앞서 언급한 논문에서는 개인정보 보호 역시 생성 데이터 평가의 척도로 삼았습니다. 그 중 한 가지 방법은 해밍 거리 (Hamming Distance)인데요. 기본적으로 두 개의 길이가 서로 같은 문자열 사이의 거리를 측정하는 척도인데, 두 데이터 사이에 익명화가 얼마나 진행되었는지를 측정하는 척도로 역시 사용 할 수 있다 합니다. 따라서 앞서 언급한 논문에서는 이 해밍 거리를 사용해 생성 데이터와 원본 데이터 사이의 익명화 척도를 측정하였습니다.
지금까지 생성 데이터를 어떤 방식으로 평가하는지를 알아보았습니다. 생성 데이터의 임상적 실사용례 몇 개를 알아보고 마치려 합니다 손가락 아파!
4. 생성 데이터의 임상적 실사용례
4.1 뇌혈관질환 관련 연구

PLoS One에서 올해 2월 나온 논문입니다. 뇌혈관질환에서 합성 데이터가 실제 데이터를 얼마나 잘 모방하는지를 측정하였는데요.
해당 논문은 허혈성 뇌졸중을 겪은 암 환자 및 비 암환자의 데이터를 합성하였는데요. 합성 데이터가 앞서 말한 원본 데이터의 인구학적 특성이나, 기저질환, 입원 기간 등 중요한 평가 척도를 유사하게 모방한다는 점을 보고했습니다. 결론에서 연구진은 합성 데이터가 가설을 생성하거나, 데이터를 공유하거나, 빅데이터에 대한 접근을 신속하고 안전하게 할 수 있는 강력한 도구임 역시 강조하였구요.
4.2. 혈액종양 관련 연구
앞서 생성 데이터의 평가 척도를 이야기 할 때 언급한 논문도 있지만 또 다른 논문도 있습니다

해당 연구진은 골수이형성 증후군 (Myelodysplastic Syndrome, MDS) 환자 데이터를 합성하여 평가하였는데요. 연구진은 조건부 생성적 적대 신경망(GAN)을 사용해 생성된 합성 데이터가 임상적 특징, 유전체 정보, 환자군에 대한 치료 및 치료 결과를 높은 정확도로 재현 할 수 있음을 시연했습니다. 특히 인상적이었던 부분은 2014년에 수집한 데이터를 기반으로 데이터 합성을 진행하여 이를 바탕으로 진행한 환자군 분류가 2024년 현재 실제 수집한 데이터를 기반해 진행한 분류와 유사했다는 부분 (아래 그림 참고)이었습니다.

지금까지 합성 데이터가 무엇인지, 어떻게 만들고 어떻게 평가하는지, 임상적 사용 용례는 어떤 것들이 있는지 등을 알아보았습니다. 확실히 빅 데이터에 대한 접근을 용이하게 할 수 있고, (합성 데이터가 실 데이터를 잘 모방한다는 전제 하에) 개인정보 보호에 대한 걱정을 던 상태로 데이터를 공유 할 수 있으며 비교적 드문 케이스를 증폭시켜 학습에 이용할 수 있다는 등 다양한 가능성이 엿보입니다만 신중한 사용 및 평가가 필요해보입니다.
해당 카테고리 다른 글 보기
더보기 →
미국내과학회 매사추새츠 챕터 (ACP MA Chapter) 학회 후기
포스터 세션에서 발표 할 기회도 얻었고, 좋은 결과 또한 얻어 뜻 깊은 시간이었다

공공데이터와 함께하는 연구생활
무슨 연구든 가장 큰 관건은 양질의 데이터를 얻는 일이다. 공공 데이터는 이 문제를 어느 정도 해결해준다.

란셋 디지털 헬스 2020 5월호 코멘트 요약 (1)
대규모 정신과 선별검사, 당뇨병성 망막병증, 그리고 의료 취약 지역에서의 설사 관리