Research
Clinical use of synthetic data
What is synthetic data and how can it be used in clinical research?

I’ve seen cases and papers where synthetic data is used for medical research purposes. To better understand this area, I did some research.
0. What is Synthetic Data?
Acquiring high-quality data is cumbersome and expensive. If you want to train a machine learning model or an artificial neural network but lack the necessary training data, it’s a common issue. Getting good data is always a task.
However, we always look for efficient ways. One attempt to train artificial neural networks without large quantities of high-quality data is by using synthetic data. Synthetic data is generated to emulate real-world data (RWD). Its advantages extend beyond just solving the data scarcity issue; it’s also seen as an alternative for preventing personal information leaks when sharing data between institutions. For instance, if Institution A shares data with Institution B, directly sharing the data could expose personally identifiable information within A’s data. However, sharing synthetic data based on A’s data ensures that crucial information in A’s data is preserved while mitigating privacy concerns substantially.
1. Synthetic Data Generation Algorithms
There are several algorithms for synthetic data generation, but one of the most well-known methods is the Generative Adversarial Network (GAN).
Generative Adversarial Network (GAN)
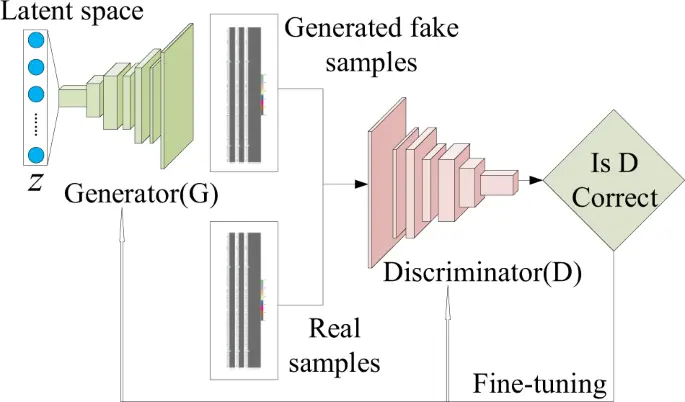
GAN consists of two neural networks, a generator and a discriminator. These two networks are in a competitive relationship where the generator creates synthetic data, and the discriminator tries to distinguish it from real data. In this process, the generator produces more realistic data, and eventually, the discriminator cannot differentiate between real and synthetic data. Advanced concepts that evolved from GAN include DPGAN (Differentially Private GAN) and CTGAN (Conditional Tabular GAN). DPGAN is designed to protect personal information in the training dataset by incorporating the concept of differential privacy. CTGAN addresses GAN’s limitation in handling categorical variables and uses conditional generation methods to model complex relationships between various data tables, thereby generating well-mixed and complex types of data.
VAE (Variational Autoencoder)
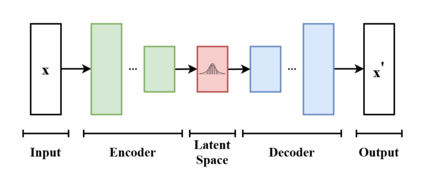
VAE is a neural network model that learns the latent space of the data to generate new data. It comprises an encoder and a decoder. The encoder transforms input data into latent variables, and the decoder generates new data similar to the original data from these latent variables. Since VAE assumes a normalized distribution for the latent space, the generated data is continuous and smooth.
SMOTE (Synthetic Minority Over-sampling Technique)**
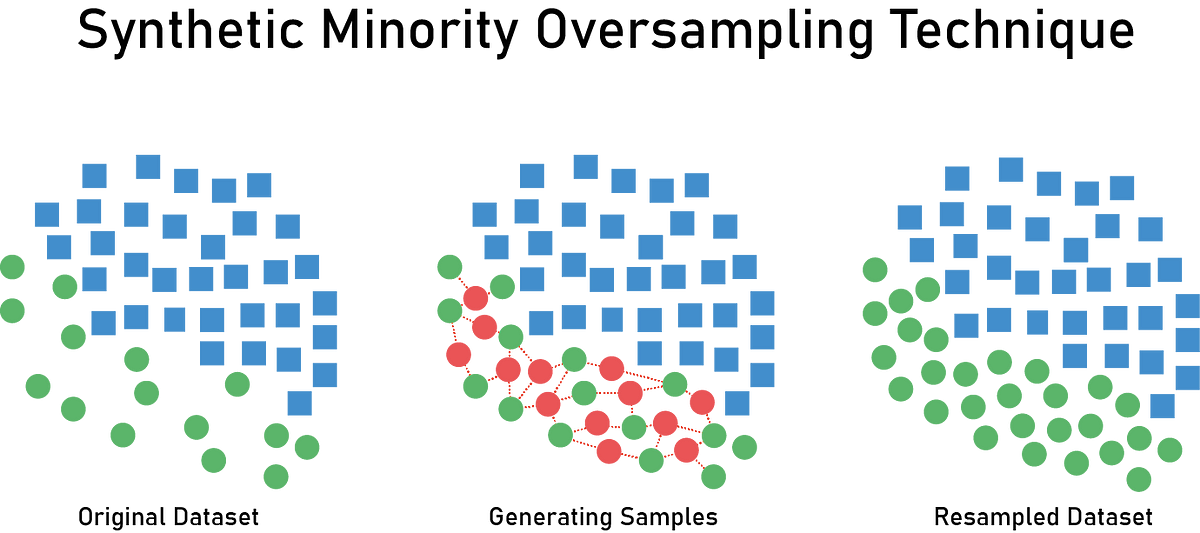
In machine learning and deep learning, there are often minority classes within datasets, such as data on rare disease patients, which are significantly fewer compared to other data. This situation is called data imbalance. SMOTE (Synthetic Minority Over-sampling Technique) is a frequently used technique to address this issue. SMOTE generates new data points between existing minority data points using the k-nearest neighbor algorithm. While SMOTE is generally used for upscaling compared to the synthetic data generation using GANs or VAEs, it still falls under the realm of synthetic data generation.
There might be other methods, but my knowledge of algorithms isn’t that extensive to cover them in detail. Let’s just acknowledge that there are various methods for now.
2. Considerations When Using Synthetic Data
While it’s great to be able to generate (realistic) data freely, significant considerations must be taken into account.
Mitigating Bias
If the original data is biased, the synthetic data will likely inherit that bias. Therefore, it’s necessary to recognize and correct any biases present in the original data when generating synthetic data. Failure to do so may result in training a model based on biased data, leading to inaccurate predictions.
Securing Representativeness
As mentioned earlier, synthetic data should be similar to real-world data. This means that the original data, which forms the basis, must also encompass a variety of situations. At the same time, the generated synthetic data should reflect these diverse situations to accurately represent the real world. This aspect is crucial for a model trained on synthetic data to perform well in real-world scenarios.
Compliance to Regulations
This is particularly important when using synthetic data for medical purposes. Synthetic data should meet the requirements of personal information and medical data regulations, such as HIPAA or GDPR. Ensuring compliance guarantees data privacy and security, especially when dealing with medical or personally identifiable data.
3. Evaluation of Synthetic Data
The first thought that came to my mind when hearing about synthetic data was:
How can we evaluate whether the generated data is similar to the real data?
Since the goal is to create and utilize realistic data, evaluating how well the synthetic data mimics and reproduces real-world scenarios is important.
A recent paper published in NPJ Digital Medicine (Mimicking clinical trials with synthetic acute myeloid leukemia patients using generative artificial intelligence) provides examples of how to evaluate synthetic data. The paper generated synthetic data on acute myeloid leukemia patients using two different algorithms (CTAB-GAN+, NFlow).
3.1. Statistical Similarity
Simply put, this measures whether the synthetic data has the same statistical characteristics as the original data. For instance, the mean age and standard deviation of the synthetic data cohort should not be significantly different from those of the original data. The aforementioned paper compares the statistical properties of the cohorts formed by synthetic and original data, as shown in the following table.

Comparison of the statistical properties between synthetic and original data
Although the details of the paper aren’t covered here, you can see a comparison to check whether the synthetic data accurately replicates statistical characteristics such as age, gender distribution, white blood cell count, etc., of the original data. The paper also evaluates whether the synthetic data preserves the genetic characteristics of the original data.

Comparison of the genetic characteristics between synthetic and original data
3.2. Structural Similarity
Additionally, it should maintain the same correlations as the original data. For example, if there is a correlation between age and a specific disease in the original data, the same should be observed in the synthetic data. The previously mentioned paper compares the similarity between synthetic and original data by analyzing the survival rates of acute myeloid leukemia patients.

Comparison of structural similarity through survival analysis between synthetic and original data
3.3. Utility
Another critical measure is whether the synthetic data serves as useful as real-world data. Ideally, a model trained with synthetic data should exhibit similar performance to one trained with real data since that’s the primary goal.
3.4. Privacy Conservation
One advantage of synthetic data is creating data with similar statistical properties to the original while protecting personal information. The previously mentioned paper also considers privacy preservation as an evaluation criterion for synthetic data. One of the methods used is the Hamming Distance, which measures the distance between two strings of equal length and can also be used to assess the degree of anonymization between two datasets. The paper uses this distance to measure the anonymization level between synthetic and original data.
We have discussed how to evaluate synthetic data. Now, let’s explore some clinical use cases of synthetic data.
4. Clinical Use Cases of Synthetic Data
4.1 Study on Cerebrovascular Diseases

A paper published in PLoS One this February measures how well synthetic data emulates real data in cerebrovascular disease research.
The paper generated synthetic data on cancer patients and non-cancer patients who had an ischemic stroke. It reported that synthetic data closely mimics key evaluation metrics such as demographic characteristics, underlying conditions, and hospital stay duration of the original data. The researchers concluded that synthetic data serves as a powerful tool for generating hypotheses, sharing data, and providing quick and secure access to big data.
4.2. Study on Hematologic Malignancies
Apart from the previously mentioned evaluation paper, another paper exists.

The researchers synthesized data on patients with Myelodysplastic Syndrome (MDS). They demonstrated that synthetic data generated using a conditional GAN could accurately replicate clinical features, genomic information, treatment, and treatment outcomes of patient cohorts. Notably, they generated synthetic data based on information collected in 2014 and combined it with classifications from 2024, highlighting its potential to reflect real-world data accurately.

We have now covered what synthetic data is, how it’s generated and evaluated, and some clinical use cases. It indeed shows promise in enhancing access to big data, ensuring data privacy, and leveraging rare cases for training. However, careful usage and evaluation are necessary.
Other posts in the same category
View All →
Review of the American College of Physicians Massachusetts Chapter (ACP MA Chapter)
In the poster session, I had the opportunity to present and also achieved good results, making it a meaningful time.

Research life with open data
In any research, the most crucial aspect is obtaining high-quality data. Public data somewhat helps solve this issue.

Summary of the May 2020 issue commentary from Lancet Digital Health (1)
Large-scale mental health screening, diabetic retinopathy, and diarrhea management in medically underserved areas